
There's no shortage of "Lossless vs. Lossy" articles on the internet. Hell, there's even one on our own blog. Most of these articles are written from the perspective of someone who listens primarily to pop, rock, or electronic music on earbuds during their commute. For that listener and that material, the honest answer is that the codec or format doesn't matter all that much, if at all. A track mastered at -8 LUFS with 6 dB of effective dynamic range played through a Bluetooth link on a train isn't going to reveal the difference between a 320 kb/s Ogg Vorbis stream (Spotify), a 256 kb/s AAC stream (Apple Music), and a lossless FLAC. The codec's features are hiding behind the mastering's failures, and both are hiding behind the train.
But here at TRPTK, we don't record that kind of music. We record a solo cello in an empty church at three in the morning. We record a string quartet with a single stereo pair, with no EQ, no compression, and a dynamic range that easily exceeds 40 dB. We master to leave headroom rather than to chase loudness. In other words, our material is essentially the absolute worst case scenario for a perceptual audio codec such as Ogg Vorbis and AAC. These perceptual audio codecs are designed around the assumption that there's going to be something loud going on to hide their errors behind, and our recordings usually don't oblige.
So the question for someone such as yourself (a listener of refined taste), is not really whether streaming codecs are "good enough". Rather, the question is: what, specifically, gets thrown away between the master we deliver and the bits that arrive at your headphones - and whether or not any of this matters for the music we record? This blog is going to be a tour of that, with spectrograms and measurements to back it up.
What streaming services actually deliver in 2026
Before we talk about what these codecs do specifically, let me give you a brief overview of the current landscape. Both major services have moved (slowly and reluctantly, might I add) towards lossless. Both still, however, deliver the vast majority of their streams in lossy formats.
Spotify's desktop and mobile app still uses Ogg Vorbis at all three quality levels: 96 kb/s (Low), 160 kb/s (Normal), and 320 kb/s (Very High, Premium Only). Spotify's web player is a bit of an odd one out, since it uses AAC at 128 kb/s. In September 2025, Spotify finally launched Lossless for premium subscribers, which offers 44.1 kHz 24 bit audio.
Apple Music's lossy tier is AAC at 256 kb/s, and has been for years. Since 2021, Apple's entire catalogue has also been available in ALAC (Apple's own lossless codec). They also offer hi-res lossless streaming at up to 192 kHz 24 bit, but what you can actually hear is an entirely other question, depending completely on your signal path. And there are lots of footnotes. AirPlay 2, as well as Apple's own AirPods, recompresses hi-res streams into 256 kb/s AAC, which is a fact Apple gladly tries to hide from you.
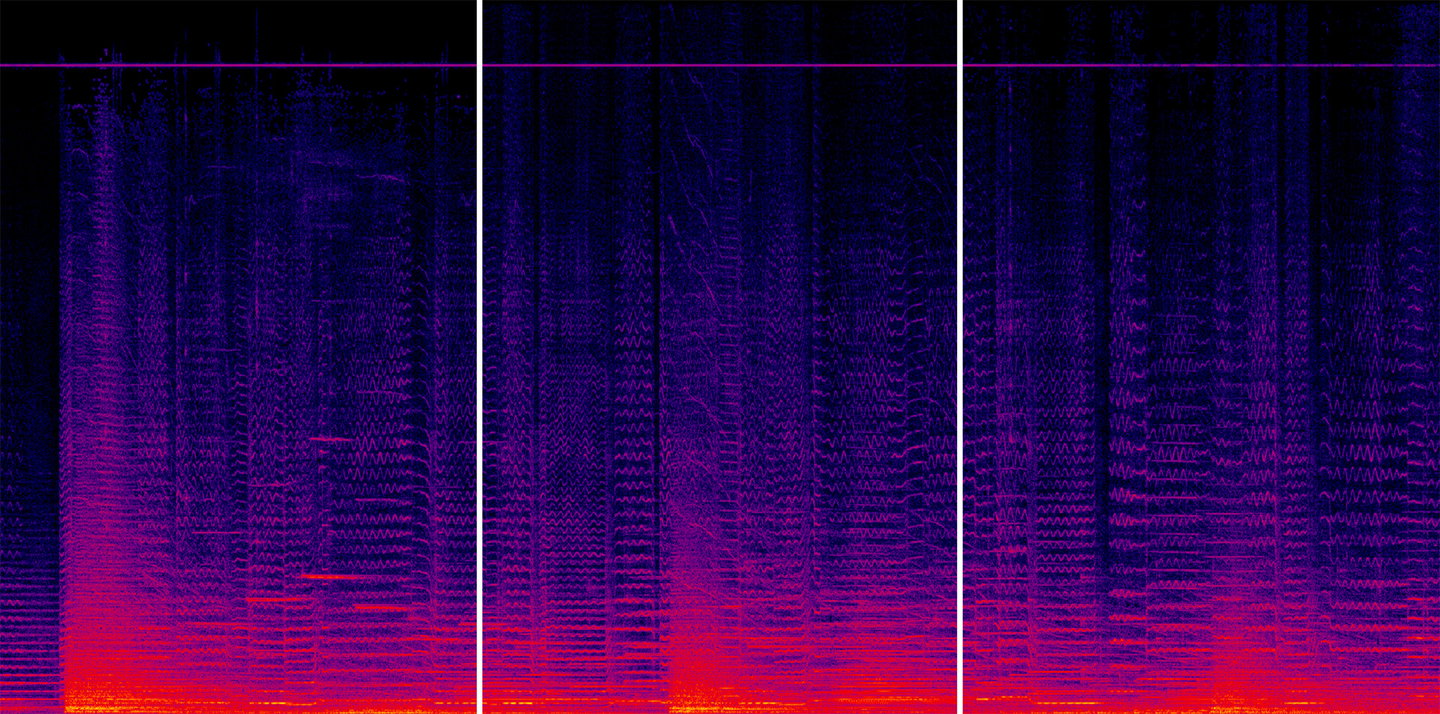
Left: Spotify Premium (Ogg Vorbis 320 kb/s);
Centre: Original FLAC;
Right: Apple Music (AAC 256 kb/s).
Do you see the pink/purple line around 20 kHz? The first five people to write us a message with the answer, get a free hi-res download voucher.
Recap: How lossy codecs actually work
Both Ogg Vorbis and AAC are perceptual codecs based on the Modified Discrete Cosine Transform (MDCT). The rough idea of these is always the same: you slice the audio into short overlapping "windows", transform each window from the time domain to the frequency domain, and then throw away the parts you hope nobody will notice.
What "nobody will notice" means is determined by a psychoacoustic model, a mathmatical description of the human hearing that predicts which frequencies will be masked by louder nearby frequencies, which quiet details fall below the threshold of audibility, and how many bits can "safely" be stripped from each frequency band without the listener noticing. The encoder then spends it bit budget where the model says it'll matter most.
This approach works beautifully for material the model was designed around, e.g. material most of the people listen to: dense, loud, spectrally rich music with a nice rug for a continuous noise floor that's perfect for sweeping errors under. But it works less well for:
Sparse material, where there's nothing loud to mask quieter artefacts;
Transient-rich material, where the mismatch between the MDCT window length and the actual event duration produces "pre-echo";
Sustained harmonic content, where the codec has to decide which spectral peaks are "real" tonal components, and which are artefacts of its own analysis;
Natural stereo recordings, where the differences between left and right channels carry spatial cues in the form of tiny decorrelated reflections (Joing Stereo coding, which assumes the L and R channels are similar most of the time, can erode this);
Extreme dynamic range, because the codec's bit allocation is tuned around an assumption of loudness-normalised programme material. Very quiet passages get bit-starved.
You see a pattern here? Every single one of these is practically our bread and butter here at TRPTK. And that's precisely the idea; the way we record is the way we record because we want these specific things to be on the record.
Bringing it to the test
To put all of this on a measurable footing, we took a small section of our recording of the third movement of Jan-Peter de Graaff's cello concerto "The Forest in April", with Maya Fridman and the North Netherlands Symphony Orchestra, and encoded it through both codecs using the same if not extremely similar encoders: Apple's own CoreAudio AAC at 256 kb/s CBR, and aoTuV-based Ogg Vorbis at Quality 9 (roughly 320 kb/s), matching exactly what Apple Music and Spotify Premium respectively actually deliver.
We then decoded each of these files back to the original format (44.1 kHz 16 bit) and subtracted it from the original. The resulting "null difference" files contain only what the codec has changed: no music, just the errors. Whatever you see or measure in a null file, is by definition something the codec added or removed.
Aside from the spectral analyses we made using Spek, we also used ffmpeg's astats command to be able to further measure the signals and differences.
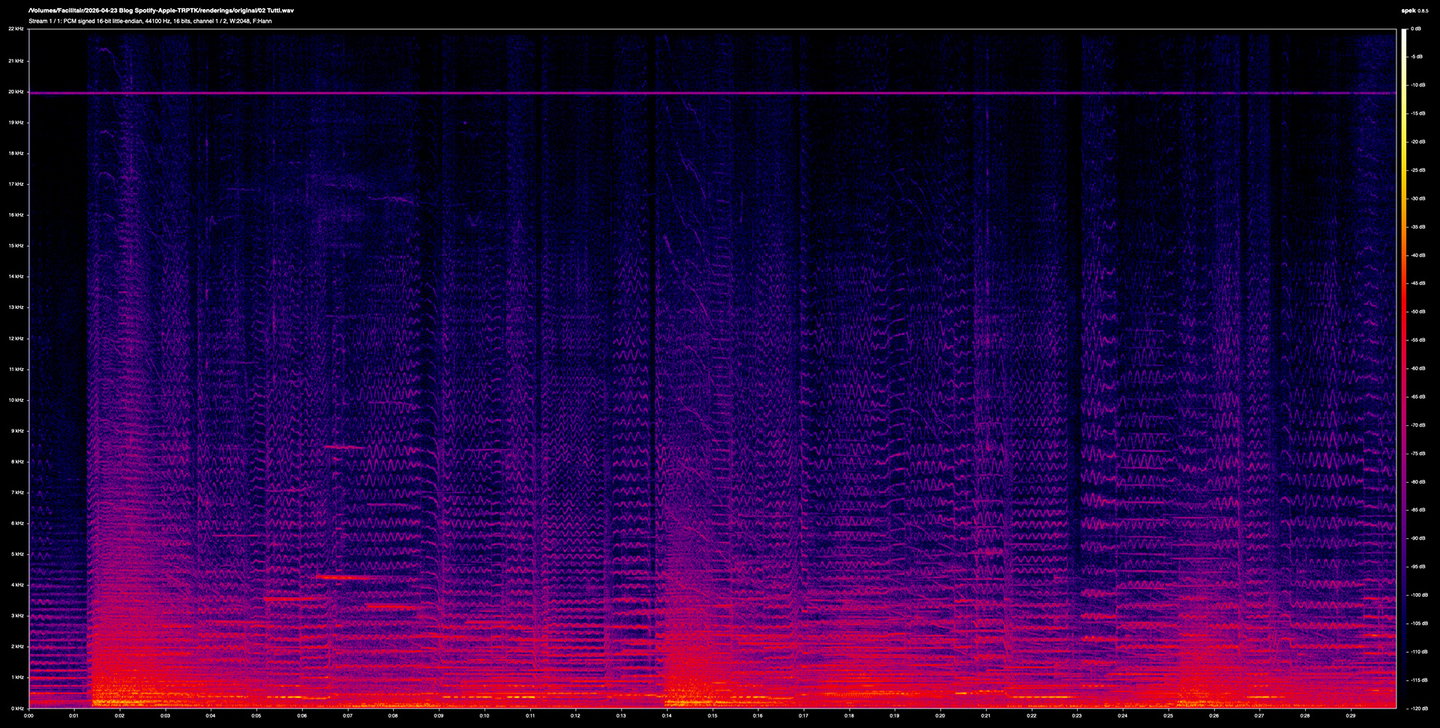
Above: a spectrogram of the original lossless file at 44.1 kHz 16 bit.
Below: a spectrogram of the Ogg Vorbis file (Spotify Premium).
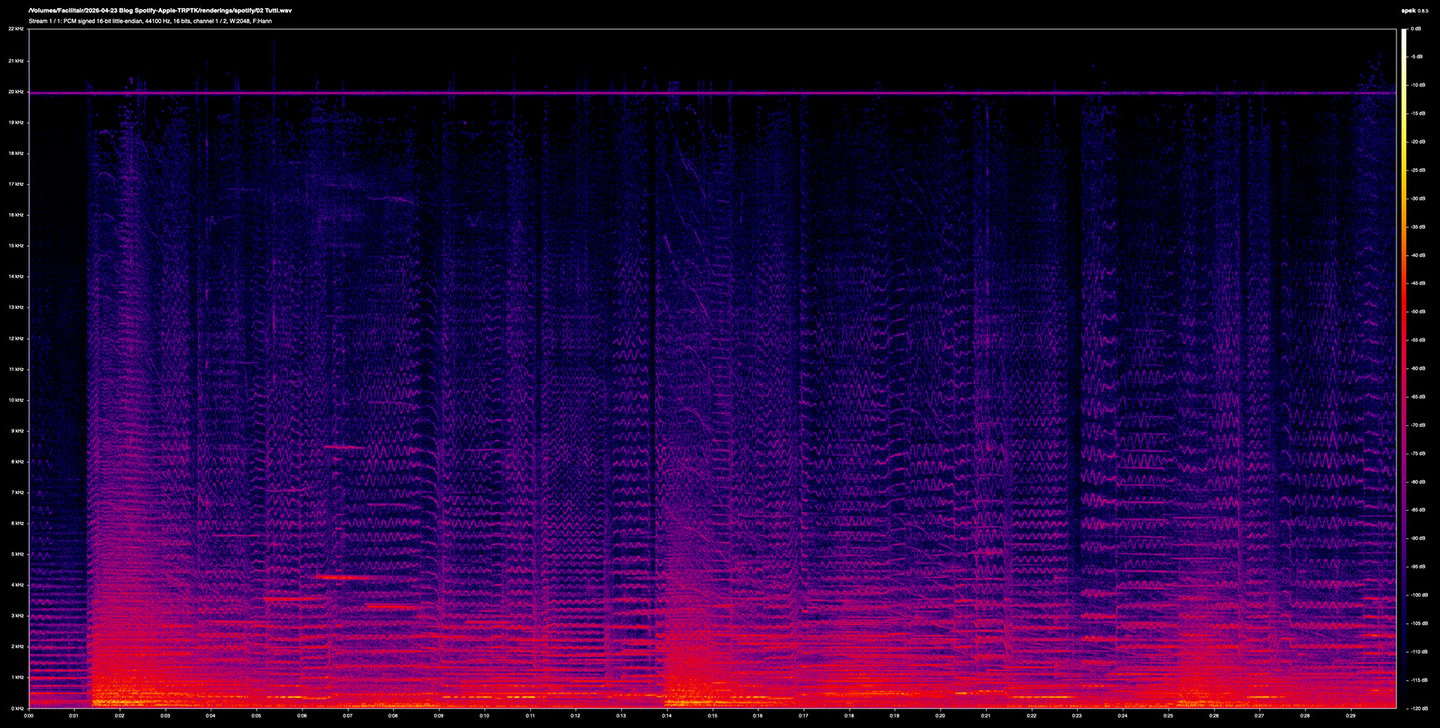
Above: a spectrogram of the Ogg Vorbis file (Spotify Premium).
Below: a spectrogram of the AAC file (Apple Music).
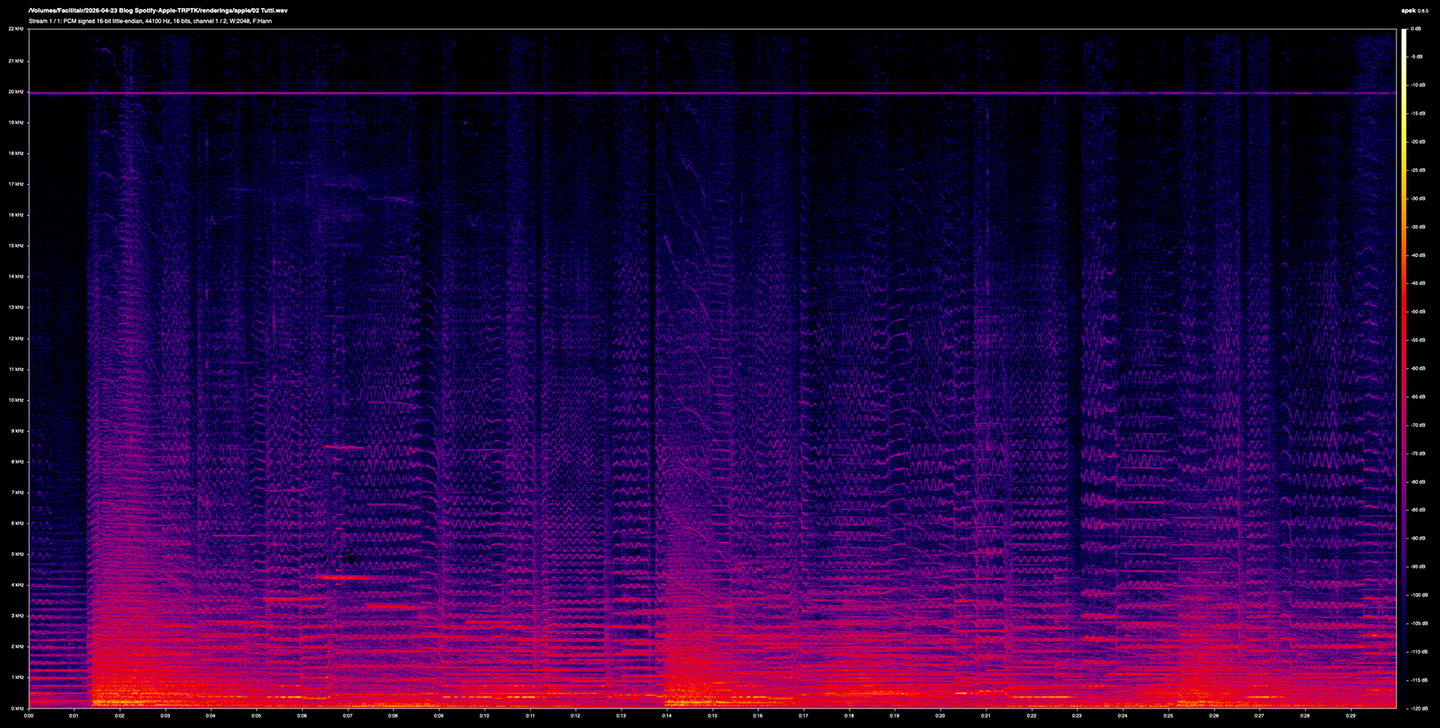
At first glance, these spectrograms of the original and the encodes are visually hard to distinguish. Overall spectral energy is preserved, dynamic shape is intact, top-octave content survives to around 20 kHz in all three (with the notable exception of some loss in the Spotify file). This, in itself, is worth stating: at their top rates, these codecs do do a genuinely impressive job of preserving the gross content of an unprocessed orchestral recording. Three decades of psychoacoustic engineering has brought us that much.
The errors only begin to show when looking at the differentials. If the codecs were perfectly lossless these would be silent, empty, black. They aren't, but they're quiet. Apple's error is clearly concentrated below 3 kHz, sitting around -105 to -115 dB during quieter passages, and rising to about -100 dB during the louder tutti section. Above 4 kHz the difference is essentially at the measurement's noise floor.
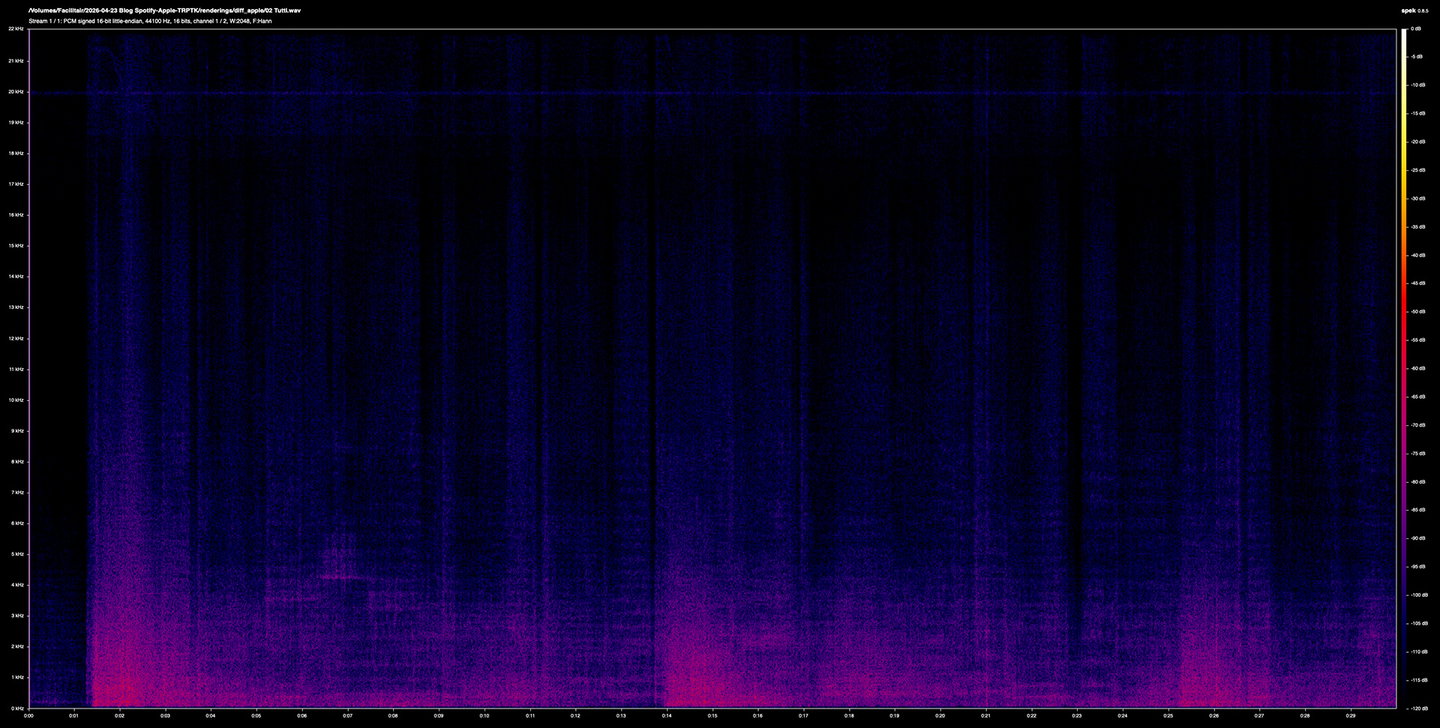
Above: the differential information between the original lossless file and Apple Music's AAC file.
Below: the differential information between the original lossless file and Spotify Ogg Vorbis file.
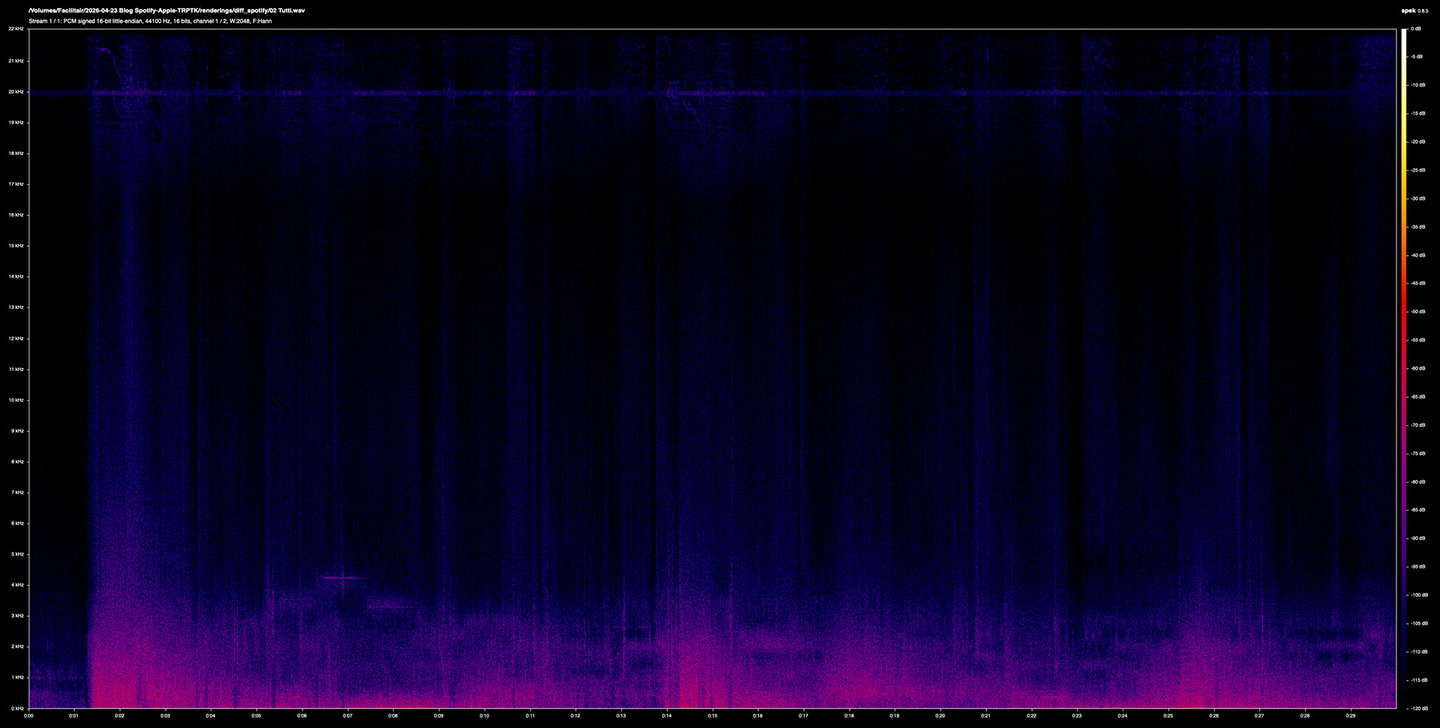
Spotify's error is much broader in frequency and more continuous in time. Energy extends well into the 3-4 kHz region even during quieter passages, and the shape of the error tracks the music more visibly. You can see the structure of the piece in a way you can't really in the Apple one.
The measurements
Running both differential files through ffmpeg's astats analyser gives us the actual numbers behind the images: Apple's AAC has an overall RMS error of -64.85 dB, with a peak error of -29.94 dB. Spotify's Ogg Vorbis has an overall RMS error of -63.22 dB and a peak error of -32.28 dB.
This is actually more interesting than the result we were half-expecting. Spotify's peak error is 2.3 dB quieter than Apple's, and its RMS peak is 2.1 dB quieter too. Apple produces sharper, more transient-clustered errors with cleaner intervals between, whereas Spotify produces a more diffuse, continuous low-level error spread across time and frequency. It does match what the Ogg Vorbis specification itself says about its characteristic failure mode: a continuous reverb-like colouration rather than discrete events. AAC, on the other hand, is much more event-driven: it lets errors spike during transients and stays quieter in between.
Zooming in further reveals each codec's character even clearer. Apple's AAC codec is tightly clustered around the first few note attacks of solos, and drops towards the noise floor between them. Spotify's Ogg Vorbis is visible throughout the decay trails, broader, higher in frequency, and more continuous. In the tutti sections, both codecs are harder at work; Apple's error stays below roughly 8 kHz and is distributed evenly, whereas Spotify's extends further up into the 20 kHz region with a visible low-frequency band below 2 kHz throughout.
Which of these trade-offs sounds better is not determined by the measurement itself, of course. The total error energy between Apple's and Spotify's is much closer than we'd originally thought, only around -1.9 dB. But the codecs are making different decisions about where to spend their error budget, not producing fundamentally different amounts of it.
What this means for the music we record
Neither codec is cleanly "better" than the other for our material. They make different trade-offs. On a solo cello passage with long decays, Spotify's codec's error might be more obtrusive than Apple's event-clustered error. On a dense tutti with lots of masking, the difference may be inaudible.
Lossy streaming is still audibly different from lossless (on good equipment, on this material). The errors we measured are small but absolutely not zero, and they live in the places listeners of this music actually listen: transient clarity, hall ambience, quiet decay tails. A 1.5 dB RMS difference between codecs may be less important than the 50+ dB difference between either codec and the lossless source.
Furthermore, talking about codecs is basically inseparable from talking about mastering. A loud, limited master sounds fine through any of these codecs because the codec's failures line up with what was already destroyed in mastering. An untouched dynamic master exposes the codec honestly, in both directions: the codec has to work harder, and you can see it working. That is part of why we record and master the way we do, and it's why these comparisons are visible at all. If we were to master like anyone else, you wouldn't see a genuine difference on a spectrogram, because there wouldn't be one worth measuring.
Lastly, the reason streaming codecs work as well as they do, for most listeners, on most music, is that most music no longer contains the kind of information codecs are worst at preserving. We still try to put that information on the record. This article exists because we think it's worth knowing what happens between us and you. Not as a complaint about streaming services, but rather as a description of the gap between a master and a delivery, honestly measured.
Thank you so much for reading. Let us know what you think about all this by getting in touch.